 Fortuit Apps
CONTACT US
Fortuit Apps
CONTACT US

How an AI Engine can improve your business
The huge technological progress of the last decade addressed and greatly
impacted the basic human need of communication. Websites, blogs, emails,
text messages, Facebook, Snapchat, Slack and smartphones on the one hand
and Google on the other as the dominant intermediary, all in essence
address our need to communicate.
I would refer to this as the
‘communication era’ that I believe has “plateaued” in terms of potential
truly disruptive innovation.
We are now at the start of the next era, the ‘knowledge era’, where
Artificial Intelligence (AI) will dominate. AI is an umbrella term that
includes multiple technologies such as Machine Learning (ML), Natural
Language Processing (NLP) and Knowledge Representation (KR).
AI is now the
cutting-edge of technology.
How can your business use AI?
Clients and potential clients invariably ask how they can use AI to add
value to their business.
The answer is by deploying an AI Engine as an
implementation vehicle through which AI functionality can be leveraged,
abstracting away the inherent complexity.
Composed of several distinct
modules, an AI Engine can be deployed either as a service (AIaaS) or
embedded within client-server, web or mobile applications.
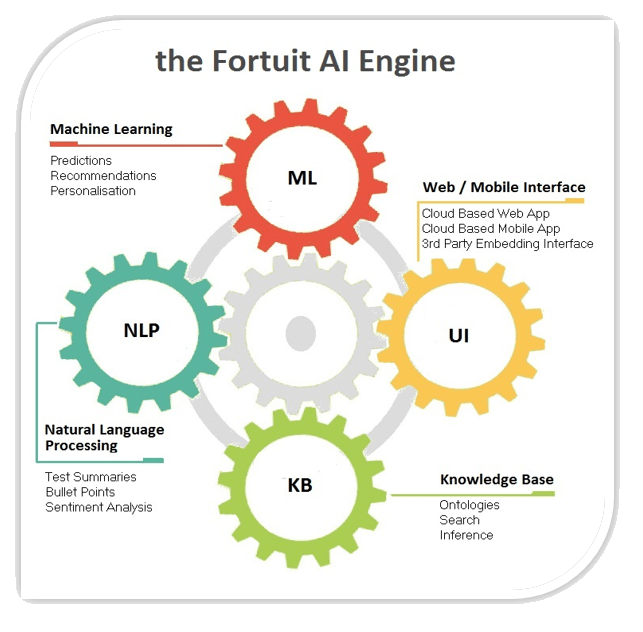
What is an AI Engine?
An AI Engine is comprised of several fundamental modules which include a
Machine Learning Module, a Natural Language Processing Module
and a Knowledge Representation (Ontology) Module.
With a view to targeting specific business objectives like increasing sales, reducing costs, addressing compliance and improving cyber security, these modules are used to collect and transform data, to generate accurate predictions and insights, to read and classify text and much more.
The Fortuit AI Engine
At Fortuitapps we have developed
a powerful, business-oriented AI Engine (as opposed to an equally important
academically oriented counterpart).
Below I will detail the AI Engine
components and describe how they can be used to improve business processes.
THE MACHINE LEARNING MODULE
Machine Learning is based on Neural Networks which model biological brain
function. A Neural Network is a net of neurons (brain cells) that are
linked to each other through connections called synapses (think of a
fishing net).
These connections have a certain strength (positive or
negative) and the combination of these will result in a neuron being turned
on (firing), or not, according to a certain threshold value (think of a
light bulb with some power cords attached: if the cumulative power is
enough the light bulb will turn on).
Human thinking is the effect of firing
(or not) of neurons.
Now, take one side of a Neural Net and turn on some neurons. Then take the
other side and again turn on some neurons. You have given the net an
example of a given input and an expected output (think of an input of 1
plus 1, and an output of 2 so as to teach it addition).
Next, give it lots
of examples and then use a specific standardized learning algorithm through
which it can learn by adjusting the power of its connections and when
neurons will fire. Once it stabilizes through many iterations, ask it to
add numbers that you haven’t taught it: it will respond with a high
probability of accuracy based on what is has learned.
In this way, given an
input dataset (e.g. images) and an output data set (e.g. a description of
these images), based on the patterns it ‘sees’ it can very accurately
answer what a new picture contains even though it has never seen it before.
How the Machine Learning Module can improve your business
The Machine Learning Module can provide:
o descriptive analytics (what happened)
o predictive analytics (what will happen)
o prescriptive insights (what should be done)
In other words, the ML Module can analyze the current state of play and
provide predictions and recommendations in respect of the future.
Specific examples of Machine Learning deployments for business purposes are
the following:
Inventory Demand Forecast
A national bakery wishes to accurately predict demand and accordingly
adjust production. Given past performance in relation to a set of factors
like time of year, weather, political situation, current events and more,
an accurate ML based demand forecast can produce measurable, significant
savings.
Reducing Product Returns
An online retail garment company wants to reduce returns on its products
based on various factors including buyer gender, age, order history, web
site visits, product interest and more.
Based on the available data,
selecting an optimal ML model to provide significant insights into what
factors precipitate returns can significantly impact profitability and
efficiency (even to the point of “discouraging” orders in real time that
have a high probability of being returned)
Product Recommendations
Perhaps the most popular applications of Machine learning are Netflix’s
movie recommendation system and Amazon’s ‘customers also bought’ feature.
Recommended products on “checkout” are selected given a very accurate
pre-assessment of what will happen (i.e. how many proposed products will
actually be purchased).
Non-Performing Loans
A huge problem lenders face, identifying potential non-performing loan
candidates before they actually become non-performing and acting
accordingly can clearly provide significant value.
Given enough historical
data including customer transactions, profile, current events, unemployment
rates, interest rates and stock market rates all fed into a selected mix of
ML models can result in the identification of potential non-performing loans at
an impressive level of accuracy.
THE NATURAL LANGUAGE MODULE
Natural Language Processing (NLP) provides computers with the ability to
understand and interpret human language in the way it is written or spoken.
The objective is to make computers as intelligent as human beings in
understanding language, recognizing speech and generating language.
Key application areas include:
o Summaries: providing text summaries that only include
main concepts. Extractive summaries use the sentences or phrases already
provided, whereas abstractive summaries use newly generated text.
o Sentiment analysis: identify the feeling, judgment
and/or opinion in given texts (i.e. negative or positive twitter posts).
o Text classification: categorize texts (e.g. news
according to domain) or compare texts with a view to identifying the group
to which it may belong (e.g. this email is spam or not).
o Entity Extraction: Identify people, places, organizations and more
How the Natural Language Processing Module can help your business
Specifically, examples of deployment of the Natural Language Processing
module in business are the following:
o
Summaries and sentiment analysis
Scraping user comments from online blogs, news
sites and forums
o
Web Crawling
target blogs, forums and news sites to extract comments related to
a specific product or company and then proceeding to automatically
summarize and analyze related sentiment with a view to providing valuable
insights in regards to products and services.
o Finding potential customers using the ‘About’ section found on may web sites
Given a list of target company web sites (for example from CrunchBase), a
specialized crawler can extract texts from the ‘About’ section, summarize
and classify these texts, and then provide insights in order to locate
those companies from the list that may be of interest as potential
customers by classifying against the ‘About’ section of current customers.
o Leveraging Email sender profile and sentiment
For each email contact, summarizing and classifying all received emails and
then feeding them to a pre-trained ML Model with a view to identifying the
way in which to respond that resonates to the contact’s personality and
writing style.
THE KNOWLEDGE REPRESENTATION / ONTOLOGY MODULE
KR is a field of AI dedicated to representing information about the world:
a conceptual characterization of the fundamental nature of reality in a
form that a computer system can use and understand.
This can be implemented in
the form of an “ontology”, which is a knowledge representation formalism
comprised of a hierarchical set of concepts and categories along with their
properties and the relations between them. In essence our knowledge of the world is an internal ontology.
The core of an AI Engine is implemented as an ontology which may be populated by default with a huge amount of general knowledge (e.g. the whole of Wikipedia in the form of DBPedia), or specific domain knowledge, like e-commerce or healthcare.
Leveraging the Knowledge Representation Module in business
Domain specific ontologies may provide significant commercial impact.
Specific examples include:
o E-commerce
On e-commerce web sites, users may search for products by names or
features, but they do not support queries such as “how to lose weight” or
“how to get rid of ants” although they may sell products for such
situations. What they need is an ontology through which concepts expressed
in natural language are mapped to products.
Similarly, customer support
could leverage the ontology using a chatbot to address queries
automatically with improved accuracy and efficiency.
o Healthcare
In Healthcare, an ontology that links symptoms, conditions, treatments, and
medications could provide significant added value to daily health care
business processes.
o Centralizing company knowledge
Most companies have a set of commonly used documents stored in a shared
directory, and also a set of documents that reside locally on employee pc’s
and laptops. These documents, perhaps word, pdf or text documents, contain
significant information that in total essentially comprise a significant digital asset.
Through an NLP/NLU system this knowledge could be gathered,
pre-processed and semantically analyzed with a view to creating a company
centralized ontology / knowledge base that can then be expanded, searched or updated.
PREVIEW: THE NATURAL LANGUAGE GENERATION MODULE
NLG is the very important next step forward of the ‘knowledge era’ referred
to above. At Fortuitapps we are now working on adding an NLG module to the AI Engine
described above.
As this is part of our commercial proprietary work I will
not present exact details but rather in the context of this article
describe our efforts in more general terms.
What is Natural Language Generation (NLG)?
NLG is the intelligent process of generating text in natural language in
response to a query or a specific user request. In order to do this, an NLG
module has to model the hardly trivial capability that makes humans
intelligent: common sense.
Without a substantial amount of everyday
knowledge about the world (or at least about a particular domain of
application), generation of natural language is not possible at the product
level.
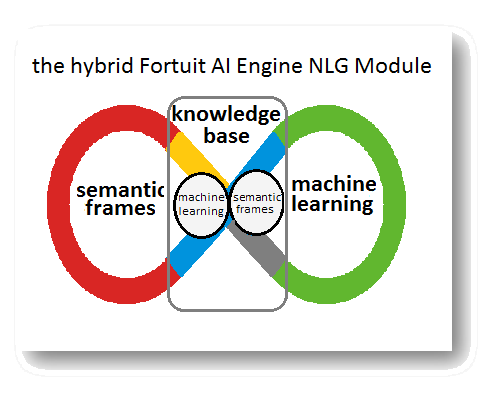
Consequently, the core of any NLG module has to be composed of a
knowledge base in the form of an ontology that provides the ‘knowledge’
that will eventually by produced as a ‘text’ response.
How do we create an NLG Core Knowledge base?
As humans learn by reading documents in any form (such as books, articles,
blogs newspapers, web sites and more) accordingly an NLG Core Knowledge
base has to be populated by machine ‘reading’ of documents.
From a machine point of view, documents exhibit a sequential structure with
multiple levels of abstraction such as headings, sentences, paragraphs and
sections. These hierarchical abstractions provide the context through which
we infer the meaning of words and sentences of text.
So, to populate an NLG core knowledge base we need software that can read
and understand corpora (e.g. Google News texts) and leverage the vast
amount of general knowledge available through Wikipedia (texts) and DBPedia
(ontology).
How can a machine read and understand texts?
In a broader sense there are two main approaches to natural language
understanding, both of which we use and which are complementary to each
other within the context of a higher level controlling module. The two
approaches are described below.
Machine Learning based approach
As described above in regards to Neural Networks, an LSTM, or Long
Short-Term Memory Network, is a kind of recurrent neural network which has
the capability to give itself feedback from past “lessons”.
An LSTM is an
extremely powerful algorithm that can classify, cluster and make
predictions about data and particularly time series and text.
We incorporate contextual features (topics) into the model to achieve
specific NLP tasks like next word or character prediction, next sentence selection, and
sentence topic prediction.
The model we use helps us answer questions, complete sentences, generate
paraphrases and provide next
utterance predictions in dialog systems.
In addition to the above deep learning models, we use “shallow” models as
implemented in Word2vec. Word2vec is a tool that gives
us a “mental map” of words, their meanings and interactions with other
words. Each word is mapped to a set
of numbers in a “number space” which
are called “word embeddings”.
Similar words are close to each other in this
number space, and non-similar words are far apart
Semantic Frame based approach
A semantic frame is a structured model of related concepts that together
provide knowledge of all of them and without which there could not be
complete knowledge of any of them.
An example would be the query “apple price forecast”: are we referring to
the price of the fruit apple or the company Apple Inc and a forecast in
relation to its stock price? In order to answer this, we must model how
humans do this, and that is by essentially using “Bayesian Inference“.
Bayesian Inference is a statistical theory in which the evidence about the
true state of the world is calculated in terms of degrees of belief known
as Bayesian probabilities.
In this context of Bayesian probabilities, in order to select the correct
conceptual frame related to the query “apple price forecast” and so know
what we are talking about we use a “Prior Primality Distribution” simply
known as a ‘prior’ of an uncertain quantity.
A prior is the probability that
would express one's beliefs about this quantity before some evidence is
taken into account.
Although there are no guarantees, given priors and structures we select the
semantic frame (either fruit price or stock price) that we deem relevant to
the query with a view to producing an appropriate response.
In our example
we are essentially asking what people usually mean by this, and so we use
the stock price semantic frame.
Generating Natural Language Text
Based on our core NLG ontological knowledge base, and combining both approaches described above, given a query or command we proceed to generate natural language text based on the following three main steps:
o Create a document plan: select concepts that will form the knowledge map
of the text to be produced
o Transform the concepts into sentences
o Filter results: Conceptual, semantic and syntactic review and adjustments
There is more to come of great interest in the field of NLG!



